![Yiorgos Chochlakis <br/> (Γιώργος Χοχλάκης ['jorɣos xo'xlakis])](https://gchochla.github.io/images/profile_new_2.png)
CLiMB: A Continual Learning Benchmark for Vision-and-Language Tasks
Published in NeurIPS, 2022
Recommended citation: Srinivasan, T., Chang, T. Y., Alva, L. L. P., Chochlakis, G., Rostami, M., & Thomason, J. (2022). CLiMB: A Continual Learning Benchmark for Vision-and-Language Tasks. Thirty-sixth Conference on Neural Information Processing Systems. https://arxiv.org/abs/2206.09059
[code]
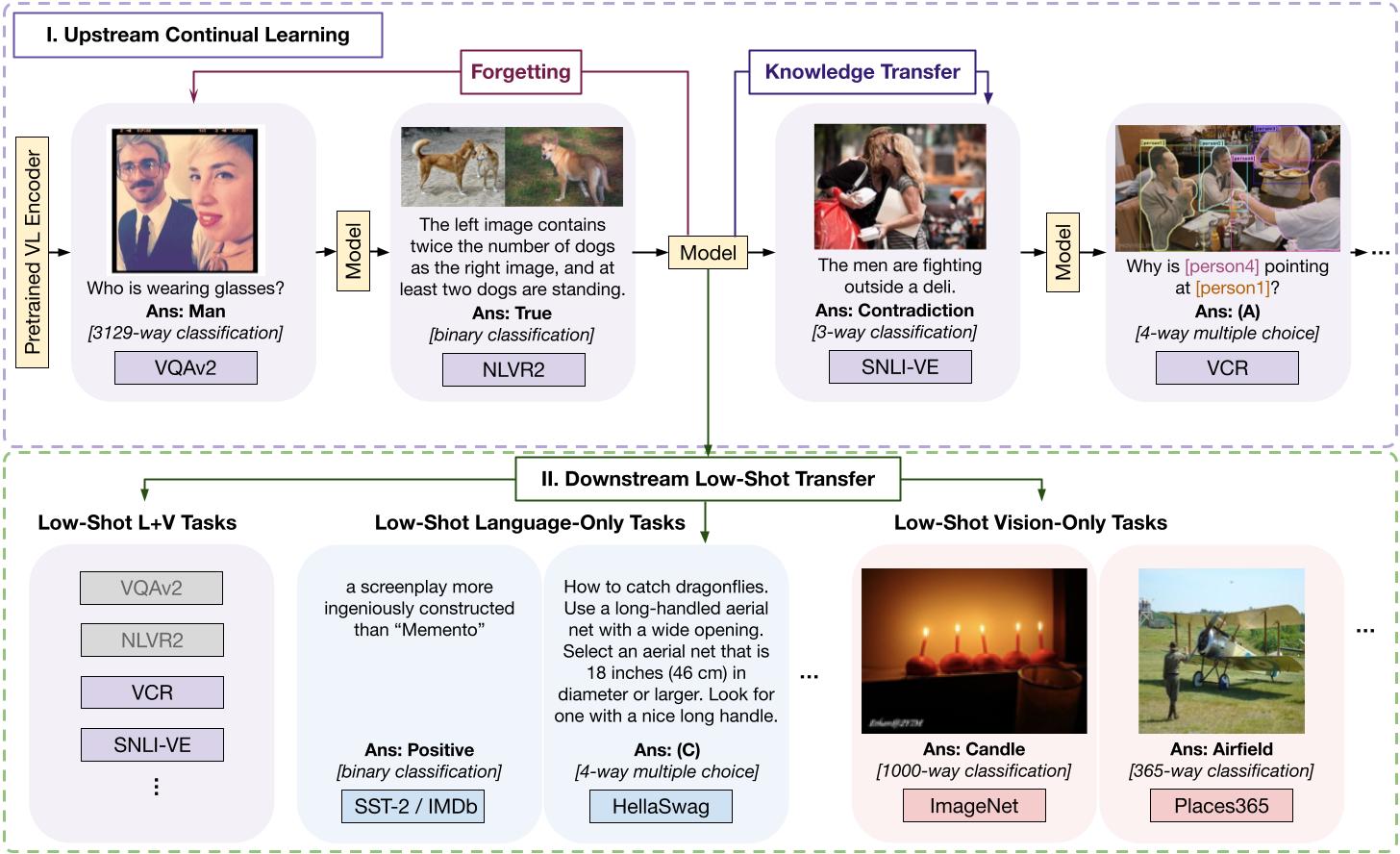
Abstract: Current state-of-the-art vision-and-language models are evaluated on tasks either individually or in a multi-task setting, overlooking the challenges of continually learning (CL) tasks as they arrive. Existing CL benchmarks have facilitated research on task adaptation and mitigating “catastrophic forgetting,” but are limited to vision-only and language-only tasks. We present CLiMB, a benchmark to study the challenge of learning multimodal tasks in a CL setting, and to systematically evaluate how upstream continual learning can rapidly generalize to new multimodal and unimodal tasks. CLiMB includes implementations of several CL algorithms and a modified Vision-Language Transformer (ViLT) model that can be deployed on both multimodal and unimodal tasks. We find that common CL methods can help mitigate forgetting during multimodal task learning, but do not enable cross-task knowledge transfer. We envision that CLiMB will facilitate research on a new class of CL algorithms for this challenging multimodal setting.
BibTex Citation
@inproceedings{srinivasan2022climb,
title={CLiMB: A Continual Learning Benchmark for Vision-and-Language Tasks},
author={Srinivasan, Tejas and Chang, Ting-Yun and Alva, Leticia Leonor Pinto and Chochlakis, Georgios and Rostami, Mohammad and Thomason, Jesse},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems}
}