![Yiorgos Chochlakis <br/> (Γιώργος Χοχλάκης ['jorɣos xo'xlakis])](https://gchochla.github.io/images/profile_new_2.png)
Tackling missing modalities in audio-visual representation learning using masked autoencoders
Published in InterSpeech, 2024
Recommended citation: Chochlakis, Georgios, Chandrashekhar Lavania, Prashant Mathur and Kyu Han. “Tackling missing modalities in audio-visual representation learning using masked autoencoders." Interspeech 2024. https://www.amazon.science/publications/tackling-missing-modalities-in-audio-visual-representation-learning-using-masked-autoencoders
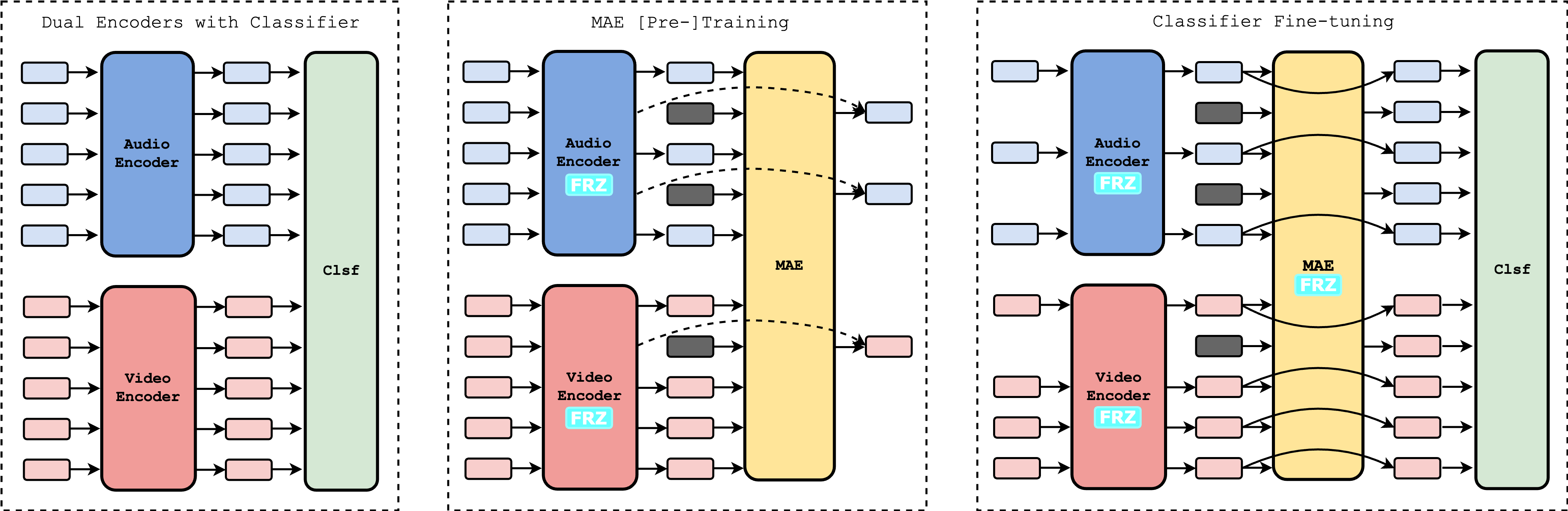
Audio-visual representations leverage information from both modalities to produce joint representations. Such representations have demonstrated their usefulness in a variety of tasks. However, both modalities incorporated in the learned model might not necessarily be present all the time during inference. In this work, we study whether and how we can make exist- ing models, trained under pristine conditions, robust to partial modality loss without retraining them. We propose to use a curriculum trained Masked AutoEncoder, to impute features of missing input segments. We show that fine-tuning of classification heads with the imputed features makes the base models robust on multiple downstream tasks like emotion recognition and Lombard speech recognition. Among the 12 cases evaluated, our method outperforms strong baselines in 10 instances.
BibTex Citation
@Inproceedings{Chochlakis2024tackling,
author = {Georgios Chochlakis and Chandrashekhar Lavania and Prashant Mathur and Kyu Han},
title = {Tackling missing modalities in audio-visual representation learning using masked autoencoders},
year = {2024},
url = {https://www.amazon.science/publications/tackling-missing-modalities-in-audio-visual-representation-learning-using-masked-autoencoders},
booktitle = {Interspeech 2024},
}