![Yiorgos Chochlakis <br/> (Γιώργος Χοχλάκης ['jorɣos xo'xlakis])](https://gchochla.github.io/images/profile_new_2.png)
Humans Hallucinate Too: Language Models Identify and Correct Subjective Annotation Errors With Label-in-a-Haystack Prompts
To appear in Main Proceedings of EMNLP, 2025
Recommended citation: Chochlakis, Georgios, Peter Wu, Arjun Bedi, Marcus Ma, Kristina Lerman, and Shrikanth Narayanan. "Humans Hallucinate Too: Language Models Identify and Correct Subjective Annotation Errors With Label-in-a-Haystack Prompts." arXiv preprint arXiv:2505.17222 https://arxiv.org/abs/2505.17222
[code]
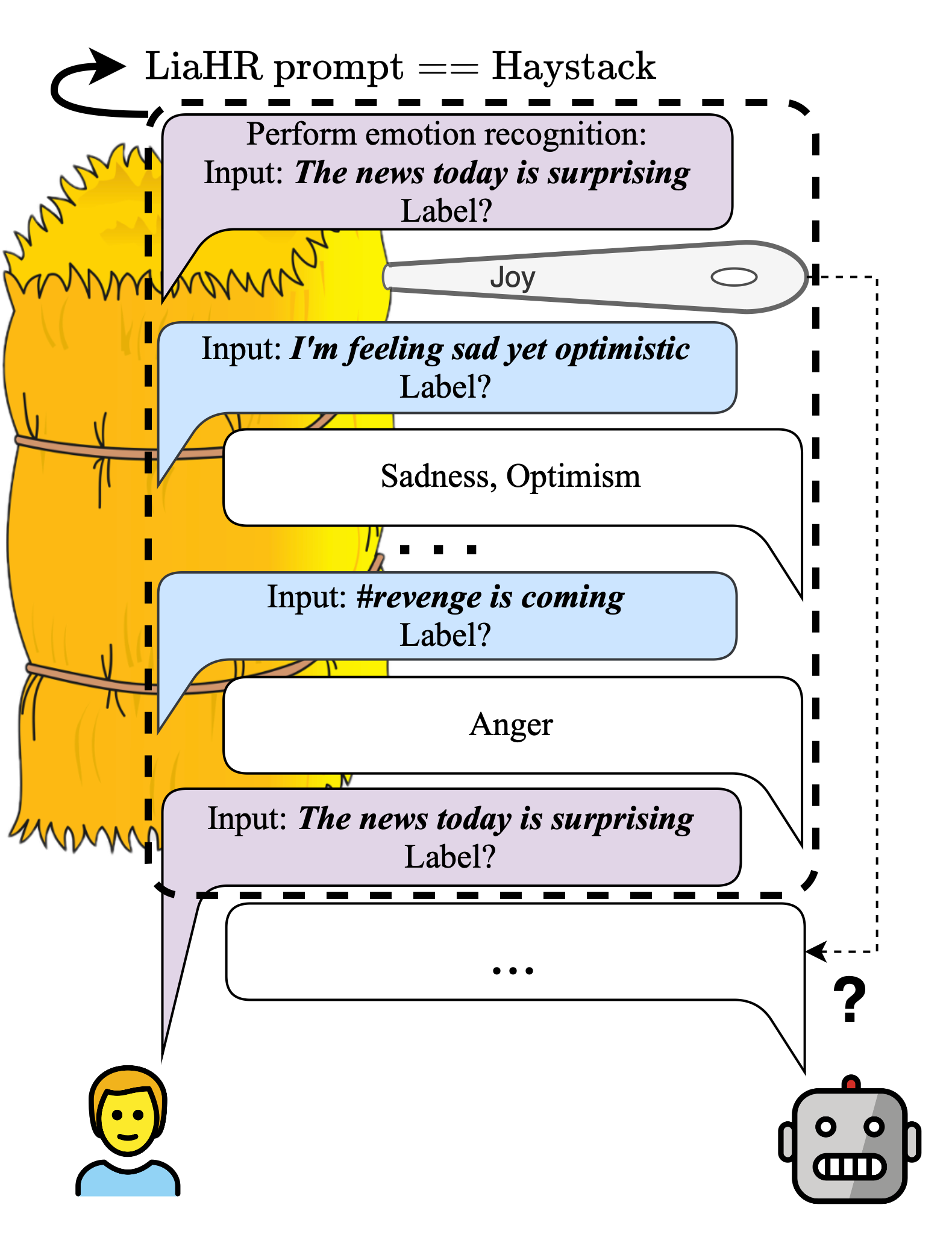
Abstract: Modeling complex subjective tasks in Natural Language Processing, such as recognizing emotion and morality, is considerably challenging due to significant variation in human annotations. This variation often reflects reasonable differences in semantic interpretations rather than mere noise, necessitating methods to distinguish between legitimate subjectivity and error. We address this challenge by exploring label verification in these contexts using Large Language Models (LLMs). First, we propose a simple In-Context Learning binary filtering baseline that estimates the reasonableness of a document-label pair. We then introduce the Label-in-a-Haystack setting: the query and its label(s) are included in the demonstrations shown to LLMs, which are prompted to predict the label(s) again, while receiving task-specific instructions (e.g., emotion recognition) rather than label copying. We show how the failure to copy the label(s) to the output of the LLM are task-relevant and informative. Building on this, we propose the Label-in-a-Haystack Rectification (LiaHR) framework for subjective label correction: when the model outputs diverge from the reference gold labels, we assign the generated labels to the example instead of discarding it. This approach can be integrated into annotation pipelines to enhance signal-to-noise ratios. Comprehensive analyses, human evaluations, and ecological validity studies verify the utility of LiaHR for label correction.
BibTex Citation
@misc{chochlakis2025humans,
title={Humans Hallucinate Too: Language Models Identify and Correct Subjective Annotation Errors With Label-in-a-Haystack Prompts},
author={Georgios Chochlakis and Peter Wu and Arjun Bedi and Marcus Ma and Kristina Lerman and Shrikanth Narayanan},
year={2025},
journal={arXiv preprint arXiv:2505.17222},
url={https://arxiv.org/abs/2505.17222}
}