![Yiorgos Chochlakis <br/> (Γιώργος Χοχλάκης ['jorɣos xo'xlakis])](https://gchochla.github.io/images/profile_new_2.png)
Modality-Agnostic Multimodal Emotion Recognition using a Contrastive Masked Autoencoder
Published in InterSpeech, 2025
Recommended citation: Chochlakis, Georgios, Turab Iqbal, Woo Hyun Kang, Zhaocheng Huang. "Modality-Agnostic Multimodal Emotion Recognition using a Contrastive Masked Autoencoder" Interspeech 2025. https://www.isca-archive.org/interspeech_2025/chochlakis25_interspeech.pdf
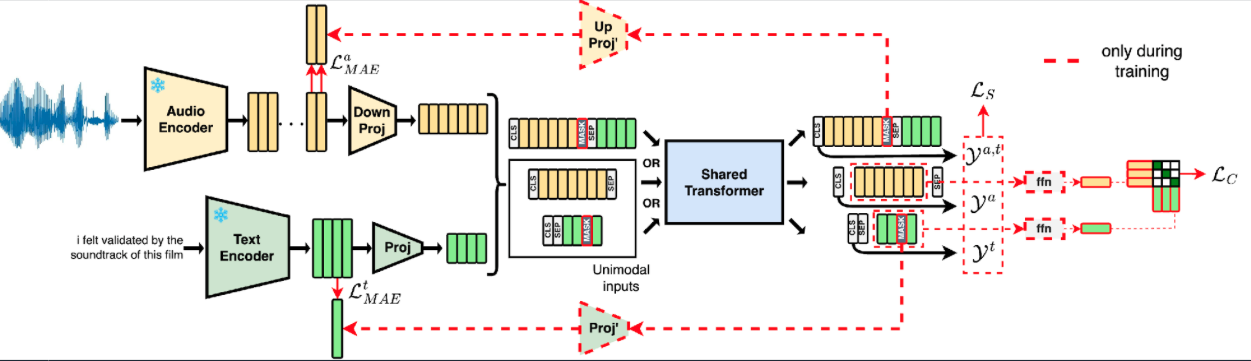
Multimodal deep learning methods have greatly accelerated research in emotion recognition and have become the state of the art. However, in many scenarios, not all modalities are readily available, leading to either failure of traditional algorithms or the need for multiple models. In this work, we advance the state of the art in emotion recognition by proposing a unified, modality-agnostic transformer-based model that is inherently robust to missing modalities. To better exploit the multimodality of the data, we propose to use contrastive learning for modality alignment and masked autoencoding for multimodal reconstruction. Experimental results on the MSP-Podcast corpus show that our unified model achieves state-of-the-art performance, and improves both unimodal and multimodal baselines by 1-5% relative in respective evaluation metrics with the capability to handle missing modalities for two emotion recognition tasks in a more compact model.
BibTex Citation
@Inproceedings{Chochlakis2025modalityagnostic,
author = {Georgios Chochlakis and Turab Iqbal and Woo Hyun Kang and Zhaocheng Huang},
title = {Modality-Agnostic Multimodal Emotion Recognition using a Contrastive Masked Autoencoder},
year = {2025},
booktitle = {Interspeech 2025},
}